People treat ChatGPT like a therapist. They type whatever is on their mind and an LLM reflects something soothing back. I wanted the same shape, except instead of generic LLM output, the user gets a real Drake lyric pulled from his actual voice. Fifteen studio projects, hundreds of songs, a man who has publicly cried on six different albums. The corpus is the punchline. The engineering challenge is retrieval: given an arbitrary conversational question, find the bar that lands.
The pitch: you type “she stopped texting me back,” the system returns four lines from HYFR about an ex texting Drake asking for closure. Played straight. Entertainment only. Lyrics © their respective rights holders.
End-to-end RAG over Drake’s catalog. This started as a homelab side project and pivoted to serverless when GPU passthrough on Proxmox got stupid (currently running the newest build, nvidia drivers are historically 6-8 months behind, any workaround WILL CRASH. Been there, done that). The point was to see how far you can go with few resources. Final bill came in under $9/mo: Workers Paid plan ($5), Vectorize storage for 44k vectors at 768d (~$3), and everything else inside free tiers (Workers AI embeddings, Groq Llama 3.3 70B for ranking, Groq Llama 3.1 8B for query classification, D1 SQLite, Pages bandwidth). Annotation of 44,161 chunks was done with Gemini 2.5 Flash on its free tier plus Claude Sonnet 4.6 via the Claude Max subscription (sunk cost, $0 marginal). There’s a false narrative that AI is incredibly expensive. The numbers at the bottom of this post say otherwise.
The Architecture
Eight steps in sequence, all on Cloudflare’s edge plus Groq for inference. No frameworks beyond Hono for routing. No agents, no chains, no LangChain.
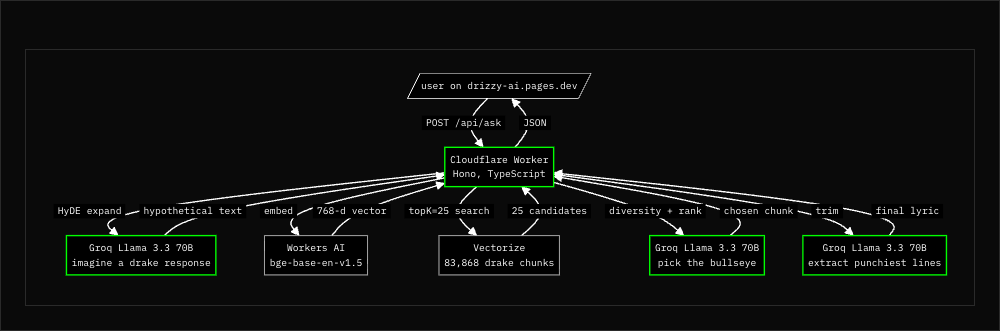
| Layer | Tool | What it does |
|---|---|---|
| Compute | Cloudflare Workers | TypeScript, Hono router, MCP endpoint, ~30ms cold start |
| Dense retrieval | Cloudflare Vectorize | 44,161 vectors at 768d, cosine similarity |
| Sparse retrieval | Cloudflare D1 + FTS5 | BM25 lexical search over the same chunks |
| Metadata filter | Cloudflare D1 chunk_meta | drake_section + role/sentiment/POV/themes per chunk |
| Embeddings | Workers AI bge-base-en-v1.5 | Query and chunks to 768d vectors |
| LLM ranking | Groq Llama 3.3 70B | HyDE expand, rank, trim (3 calls per query) |
| Query classifier | Groq Llama 3.1 8B Instant | Tags user input into the same schema as chunks |
| Frontend | Cloudflare Pages | Single index.html, vanilla JS, no build step |
| Annotation | Gemini 2.5 Flash + Sonnet 4.6 | 44,161 chunks labeled with role/sentiment/POV/themes |
Scraping The Catalog
Genius has an API but it returns metadata, not lyrics. To get the actual text you scrape the song’s page. The Python lyricsgenius library handles this politely.
First attempt: I paginated artist_songs and stopped when a page returned fewer items than the page size, assuming end of data. Wrong assumption.
# Wrong: stops at 99 because page 2 returns 49 of 50
if len(batch) < per_page:
break
# Right: trust the API's next_page token
if resp.get("next_page") is None:
break
page = resp["next_page"]Drake’s full Genius catalog goes 43 pages deep. First version found 99 songs. Fixed version found 1,889. Same code path, one boolean flip.
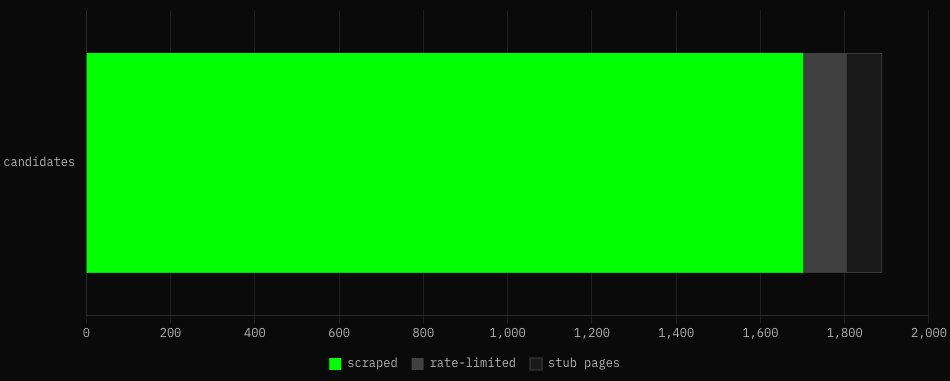
1,702 of those scraped cleanly (187 stub pages and rate-limit failures dropped). But not all 1,702 are Drake songs. That count includes every track he appears on as a guest. Properly classified: 806 are Drake-primary, the other 896 are features on someone else’s track. That distinction matters and I had to fix it in Step 6.
Chunking, and the oxtail problem
A “chunk” is the unit of retrieval. Get the size wrong and the whole pipeline suffers. The first version used a fixed 6-line sliding window, it worked great for emotional questions. It failed miserably on punchline questions where the bullseye is just 2-3 lines. I asked the live site “what should I eat today?” and got:
Fucking crazy
Drake, Calling For You · 2023
And then, I go on that wack-ass vacation
The chef is feeding us the same meal every day like I was, like, in jail still or something
I’m like, “Why are we eating jerk chicken and oxtail every single day, can we switch it up?”
No, the oxtail was fire though, but can we switch it up?
I can’t eat that shit every day, what?
Right song, right section, but the chunk diluted the punchline. The two-line bullseye (“can we switch it up? I can’t eat that shit every day“) would have been the perfect response.
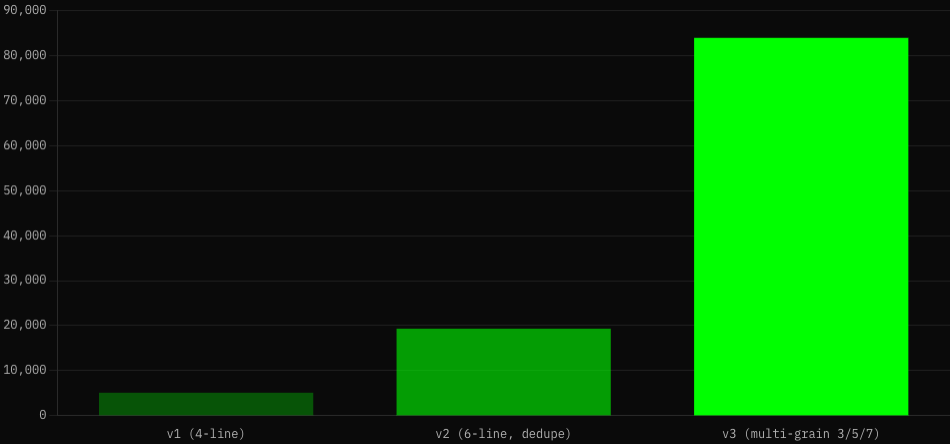
Fix: multi-granularity chunking. Re-chunk at three window sizes simultaneously (3, 5, 7 lines), stride 2, dedupe globally. Retrieval now picks the right size on cosine similarity.
Embedding + Dense Retrieval
Each chunk goes through @cf/baai/bge-base-en-v1.5 (BAAI’s General Embeddings, the English RAG workhorse). 768-d vectors, normalized for cosine. Free Workers AI handles ~10k neurons/day, plenty for live queries (~1 neuron per question). The one-time 44k-chunk burst is done via REST.
At query time: env.LYRICS.query(vector, { topK: 25 }) returns the 25 nearest chunks in ~30ms.
BM25 Sparse Retrieval + RRF fusion
Dense vector search smears rare terms and proper nouns. “Toronto” gets embedded as a generic “place” vector. “Oxtail” barely registers. Add a sparse layer.
Cloudflare D1 supports FTS5, SQLite’s full-text-search virtual table with built-in BM25 ranking. tokenize = 'porter unicode61' means “running” matches “ran” via stemming. At query time, sparse runs in parallel with dense:
const [denseMatches, sparseMatches] = await Promise.all([
env.LYRICS.query(vector, { topK: 25 }),
env.DB.prepare(
`SELECT id, text, song, rank FROM chunks
WHERE chunks MATCH ? ORDER BY rank LIMIT 25`
).bind(escapeFts5(question)).all(),
]);Fused via Reciprocal Rank Fusion, a dead-simple algorithm:
function rrf(dense, sparse, k = 60) {
const scores = new Map();
dense.forEach((it, i) => scores.set(it.id, { item: it, score: 1 / (k + i + 1) }));
sparse.forEach((it, i) => {
const prev = scores.get(it.id);
const contrib = 1 / (k + i + 1);
if (prev) prev.score += contrib;
else scores.set(it.id, { item: it, score: contrib });
});
return [...scores.values()].sort((a, b) => b.score - a.score).map(x => x.item);
}No weights, no calibration, just k=60 from the original paper. For “i miss toronto” the sparse retriever surfaces lines containing “Toronto” verbatim that dense had buried; RRF combines both and city bars float to the top.
HyDE, Crossing The Style Gap
Vector search assumes query and corpus live in the same stylistic neighborhood. That holds for technical questions over technical docs. It breaks when you’re searching Take Care for “why does she keep coming back.”
HyDE (Hypothetical Document Embeddings, Gao et al. 2022) is an elegant fix. Don’t embed the question. Embed a hypothetical answer to it, written in the documents’ style.

Heres the kicker… the mind-bending part. The LLM’s hypothetical response might be totally hallucinated fake Drake. That’s absolutely fine, you never show it to the user. You only use its embedding to find real chunks that are stylistically nearby.
drake_section filter: fixing the corpus purity problem
This was the biggest single quality lever. Initially I scraped all 1,702 tracks Drake appears on, but when he’s a feature on someone else’s song, my scraper pulled the WHOLE song lyrics: Travis Scott’s verses on SICKO MODE, Lil Wayne’s bars on Tunechi’s Room, 21 Savage’s hook on Issa. Then chunked and indexed all of it tagged as “Drake.”
The result was that the live system was returning 21 Savage lyrics in response to user heartbreak queries because Drake happens to be on the same track. Brutal.
Fix: parse the section headers Genius preserves on every page ([Verse 1: Drake], [Chorus: Travis Scott], [Hook: Drake & PartyNextDoor]) with a regex, and for feature tracks keep only sections attributed to Drake. Drake-primary tracks stay whole.
SEC_RE = re.compile(r"^\s*\[([^\]]+)\]\s*$", re.MULTILINE)
DRAKE_RE = re.compile(r"\b(drake|aubrey|champagne papi)\b", re.IGNORECASE)
def drake_only_text(lyrics):
matches = list(SEC_RE.finditer(lyrics))
if not matches: return ""
parts = []
for i, m in enumerate(matches):
header = m.group(1)
artists = header.split(":", 1)[1].strip() if ":" in header else ""
if not DRAKE_RE.search(artists): continue
start = m.end()
end = matches[i+1].start() if i+1 < len(matches) else len(lyrics)
body = lyrics[start:end].strip()
if body: parts.append(body)
return "\n\n".join(parts)I also whitelisted just 25 frequent collaborators (Lil Wayne, PartyNextDoor, Future, Kanye, Rick Ross, Nicki Minaj, Travis Scott, Rihanna, Kendrick, French Montana, Chris Brown, Beyoncé, Big Sean, DJ Khaled, 21 Savage, Eminem, J. Cole, A$AP Rocky, 2 Chainz, Meek Mill, Wiz Khalifa, J Hus, Sexyy Red, Lil Baby, Lil Yachty). Other one-off features got dropped entirely.
Result: 1,702 → 1,015 tracks, 83,868 → 44,161 chunks. Each surviving chunk gets drake_section=1 in D1’s chunk_meta table. Worker filters at retrieval time.
per-chunk annotation + polarity filter
Even with corpus purity fixed, one failure mode persisted: polarity inversion. Surface keywords match but Drake is in the opposite emotional role from the user.
Each of the 44,161 chunks gets labeled with:
- r (speaker role):
aactor /ssubject /oobservational - s (sentiment): heartbreak / triumph / loneliness / anger / regret / anxious / confident / boasting / neutral
- p (POV): 1st / 2nd / 3rd / mixed
- to (addressed to): lover / self / rival / fan / team / mother / none
- t (themes, 1-2): love, money, fame, family, city, vices, etc.
At query time a fast Llama 3.1 8B Instant call classifies the user’s message into the same schema (separate Groq quota from the 70B used elsewhere). The worker JOINs chunk_meta and filters by polarity compatibility:
const userMeta = await classifyUserQuery(env.GROQ_API_KEY, question);
// userMeta = { r: 's', s: 'H', t: ['love', 'ghosting'] }
const okRoles = COMPAT_ROLE[userMeta.r]; // user subject → ['s', 'o']
const okSentiments = SENTIMENT_GROUPS[userMeta.s]; // H ~ [H, L, R, X]
const drakeOnly = fused.filter(c => metaMap.get(c.id)?.drake_section === 1);
const eligible = drakeOnly.filter(c => {
const m = metaMap.get(c.id);
return okRoles.includes(m.r) && okSentiments.includes(m.s);
});Cascading fallback: if polarity filter starves the pool, fall back to drake-only. If THAT starves, fall back to unfiltered. Never run dry.
The polarity fix, before and after
Test query: “she stopped texting me back”. User is the ignored party (role = subject, sentiment = heartbreak).
BEFORE (pre-filter, Llama self-judged): Issa (21 Savage feat. Drake)
Score 1. Polarity inverted, the lyric is the speaker telling someone ELSE to stop texting them. Surface keyword match overruled the emotional reality.
“Girl, stop textin’ me so much, issa annoying”
AFTER (drake_section + polarity filter): HYFR (2012)
Score 4. Drake reflecting on an ex’s behavior, same emotional register as user.
“And now she’s texting me asking for closure, damn / She say this shit gon’ catch up to me, I keep tissue paper”
The Issa lyric is now structurally impossible to surface. Its drake_section is 0 (it’s a 21 Savage track, not Drake’s voice), so the filter drops it before the ranker ever sees it.
diversity dedup + LLM rank + LLM trim
Final pipeline tail. Diversity dedup caps at 2 chunks per song in the ranker pool. Without this, a single song dominates and the ranker picks from a homogeneous set. LLM ranker (Llama 70B) picks the bullseye with a sharper specificity-first prompt. Then a final LLM trim extracts the punchiest 2-4 contiguous lines, with a substring check to guard against hallucination.
The frontend
This is where I got to have some fun. Whats more fitting than a Toronto skyline, ChatGPT-style chat UI with a sidebar for history (localStorage) and 👍 👎 buttons on every response (POSTs to /api/feedback, stored in D1 alongside traces).
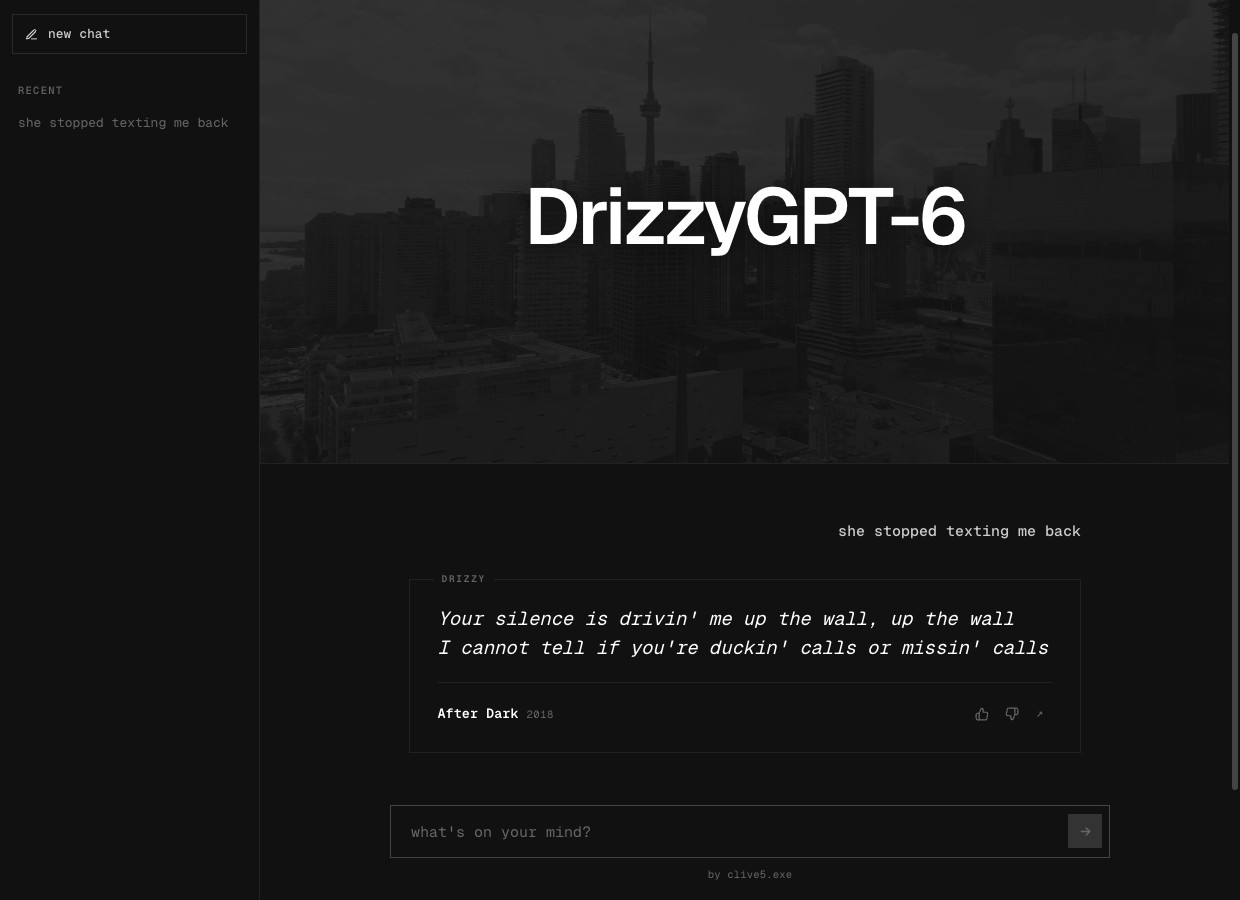
Try it live: drizzygpt6.daytona-lab.com
Measuring it: the lift, honestly
50-question golden set initially, expanded to 150, scored by an LLM-as-judge. The first iteration used Groq Llama 3.3 70B as the judge, the same model as the ranker, which is a methodological mistake (self-preference bias). Llama gave 41 of 50 perfect fives. Headline number: 4.78. Suspicious.
Swapped to Claude Opus 4.7 as judge. Different model family, no self-correlation. On the same 50 questions: 16 fives (not 41). Mean dropped to 3.37. That’s the honest baseline. The score going DOWN after fixing the methodology is the better engineering story than going up.
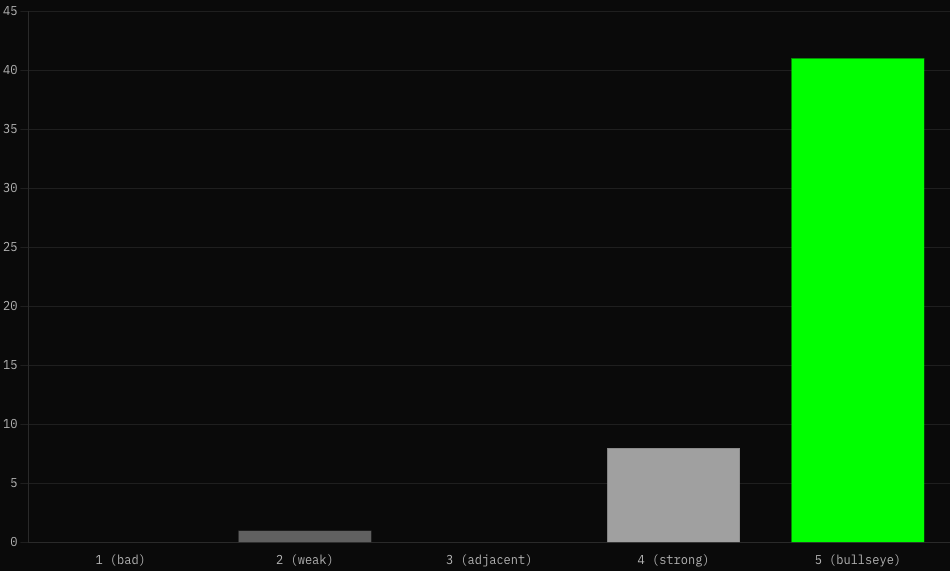
Expanded to 150 questions, ran through the v6 pipeline (drake_section + polarity filter), scored as Claude Opus 4.7 again. Final numbers:
Metric v5 baseline v6 (current) Δ
─────────────────────────────────────────────────────────
mean score 3.37 / 5 3.67 / 5 +0.30 (+9%)
precision @1 (≥4) 52% 55% +3pp
bullseyes (5s) 40 51 +11
disasters (1s) 16 8 −8 (halved)
distribution 16/31/25/38/40 8/18/41/32/51
per-category:
confidence/swagger 4.33 → 4.67 (Drake's home register)
loneliness 3.95 → 4.10
fame-cost 3.73 → 3.85
romance/heartbreak 2.76 → 3.40 (+0.64, polarity fix biggest win)
impostor/anxiety 2.80 → 3.25 (+0.45)
adversarial: off-topic 1.75 → 1.50 (still bad by design, see below)The biggest visible win: disasters (score-1 responses) cut in half. That’s the structural filter doing its job. Wrong-artist chunks and wrong-polarity chunks can no longer reach the ranker, so the worst failures (returning a 21 Savage lyric, or a polarity-inverted Drake bar) are now structurally impossible.
Where it still misses
The remaining 8 disasters cluster in:
- Off-topic adversarial (4 of 8). The product is hard-coded to always return a lyric. “Best italian restaurant in toronto” returns an OVO Sound Radio tracklist. Fix: add an intent classifier that refuses non-emotional inputs.
- Homonym confusion (1). “I miss my dog” returns “I show love to my dogs.” Drake’s “dogs” = crew, not pet. Needs query intent disambiguation.
- Edge polarity cases (3). “She ran the streets behind my back” → One Dance “Streets not safe / But I never run away”. Surface keyword match, role-inverted. The polarity filter has imperfect coverage on un-annotated chunks (they pass through), so a few slipped.
Observability
Every request writes a trace row to D1: question, HyDE text, user-classification result, top candidates, filter status, chosen chunk, per-step latencies, final trimmed lyric. The frontend’s 👍 👎 buttons POST { traceId, rating } to /api/feedback, joined back to the trace. Downvoted queries become next-round regression tests.
What it costs
# monthly bill at 1,000 user questions/day
workers paid (base) $5.00
vectorize storage $1.62 # 34M dims above 5M free
vectorize queries $0.00 # under 30M/mo free
workers AI embeds $0.00 # 10k/day free, ~1k/day used
groq llama 70b (ranker) $0.00 # 14k/day free
groq llama 8b (classifier) $0.00 # separate 14k/day free
d1 storage + queries $0.00 # under 5GB / 5M reads free
pages bandwidth $0.00 # unlimited free
-----
total $6.62 / moOne-time annotation cost: Gemini 2.5 Flash on free tier handled most of 83k chunks (1,500 RPD daily quota), Claude Sonnet 4.6 via Max subscription handled the rest. Total marginal cash: $0.
At 10,000 users a day, around $12-15/mo. At 100,000 (genuine virality), around $40-80/mo. Free-tier composition holds well into real traffic.
Try it / read the code
- 🔗 Live: drizzy-ai.pages.dev
- 💻 Source: github.com/clive5exe/dirzzyGPT6
Built with Cloudflare Workers, Vectorize, Workers AI, D1, Groq, Gemini Flash, Claude Sonnet, and a Python venv. Drake unaffiliated. For entertainment only.